Using the structured output feature of LLMs
Introduces the structured output feature for LLMs and how JSON schemas make it easier to pass model results into downstream systems. Builds a book recommendation demo with Pydantic models and the OpenAI Python SDK to enforce predictable responses. Expands to an Azure DevOps scenario that turns a user story into epics, features, and tasks, then creates the work items via the SDK. Shares practical lessons about validation, schema design, and chaining LLM outputs into existing workflows.
A number of LLM providers, including OpenAI, offer a powerful feature called Structured Output. This feature allows you to specify a JSON schema that the model response will adhere to. Having the LLM’s output in a defined format opens up a lot of possibilities for connecting LLMs to existing systems.
Below I’ll first go through a simple example to demonstrate the structured output feature. Then I’ll show a more complex example where we use the LLM’s structured output as input to a different system. Both examples are in Python and use the official OpenAI Python SDK.
Example One: Recommendations

Let’s start with a small example. Let’s say we are building an app for users to track their books. We’d like to add a recommendation feature so users can discover additional books to read (or listen to). LLMs are great at recommending content given some examples, so we’ll send the LLM a list of books that the user indicated they enjoyed and ask for recommendations. Using the structured output feature, we can ensure that the response we get back will be a list of books that we can easily incorporate into our app.
First, let’s define our models using pydantic (included as a dependency of the OpenAI Python SDK). The SDK will automatically do the conversion to a JSON schema for us when we use the structured output option.
1
2
3
4
5
6
7
8
9
10
from pydantic import BaseModel
class Book(BaseModel):
""" A class representing a book with a title and an author. """
title: str
author: str
class BookRecommendations(BaseModel):
""" A class representing a list of book recommendations. """
books: list[Book]
Now, we can send a query to the model and specify that we want the response to match the BookRecommendations schema. The OpenAI Python SDK will take care of converting the model’s JSON response into an instance of our class; all we have to do is use the output_parsed attribute of the response object.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
import os
from dotenv import load_dotenv, find_dotenv
from openai import OpenAI
# You'll need an OPENAI_API_KEY defined in an .env file
load_dotenv(find_dotenv())
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("Please set the OPENAI_API_KEY environment variable.")
client = OpenAI()
SYSTEM_PROMPT = """
You are a helpful assistant that can provide book recommendations.
You will be given a list of books and their authors that the user
enjoyed, and you should recommend one to five new books for the
user to read. The recommendations should be based on the the books
they previously enjoyed reading.
"""
USER_PROMPT = """
Books I like:
1. "Dune" by Frank Herbert
2. "Hyperion" by Dan Simmons
3. "The Expanse" by James S.A. Corey
4. "Excession" by Iain M. Banks
5. "The Three-Body Problem" by Liu Cixin
"""
recommendations = client.responses.parse(
model="gpt-4o",
input = [
{ "role": "system", "content": SYSTEM_PROMPT },
{ "role": "user", "content": USER_PROMPT }
],
text_format=BookRecommendations,
).output_parsed # type: BookRecommendations | None
if recommendations is None:
print("OpenAI did not complete the request.")
else:
print("Recommended Books:")
for book in recommendations.books:
print(f"- {book.title} by {book.author}")
# get the JSON representation of the response
recommendations_json = recommendations.model_dump_json(indent=4)
print("\n")
print(recommendations_json)
We get the following output:
1
2
3
4
5
6
Recommended Books:
- Foundation by Isaac Asimov
- Snow Crash by Neal Stephenson
- The Left Hand of Darkness by Ursula K. Le Guin
- Consider Phlebas by Iain M. Banks
- Red Mars by Kim Stanley Robinson
Followed by the JSON representation of our BookRecommendations model:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"books": [
{
"title": "Foundation",
"author": "Isaac Asimov"
},
{
"title": "Snow Crash",
"author": "Neal Stephenson"
},
{
"title": "The Left Hand of Darkness",
"author": "Ursula K. Le Guin"
},
{
"title": "Consider Phlebas",
"author": "Iain M. Banks"
},
{
"title": "Red Mars",
"author": "Kim Stanley Robinson"
}
]
}
Example Two: Agile Planning Assistant
Let’s try something more ambitious. At work, we use Azure DevOps for agile development. Building out an epic, the top-level work item in DevOps, can be a somewhat tedious process of filling out forms for potentially dozens of child items such as features, user stories, spikes, and tasks. Each item needs a title, description, and typically a few other fields.
If we can write up a detailed description of a project, why not just ask the LLM to act as an agile planning assistant and build out the epic for us? With structured outputs, we could get back a hierarchy of features, user stories, spikes, and tasks. We could even use the Azure DevOps Python SDK to take the LLM’s proposed build-out and create it in Azure DevOps!
The first thing we need to do is define some basic classes to represent the DevOps build-out, with very minimal extra fields.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class Task(BaseModel):
"""Task model."""
title: str
description: str
class UserStory(BaseModel):
"""User story model."""
title: str
description: str
acceptance_criteria: str
story_points: str
tasks: list[Task]
class Spike(BaseModel):
"""Spike model."""
title: str
description: str
tasks: list[Task]
class Feature(BaseModel):
"""Feature model."""
title: str
description: str
user_stories: list[UserStory]
spikes: list[Spike]
class Epic(BaseModel):
"""Epic model."""
title: str
description: str
features: list[Feature]
Let’s see what we get back when we provide a relatively simple project description:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
client = OpenAI()
SYSTEM_PROMPT = """
You are an expert agile assistant that can help with
creating an epic given a project description. Epics
have associated features, which in turn have user
stories and spikes. User stories and spikes have
associated tasks. You will be provided a project
description. Create an epic with the appropriate
features, user stories, spikes, and tasks.
"""
USER_PROMPT = """
Project Description:
We are building a recommendation feature in our book
management application. Our application allows users
to track books they have read, want to read, and are
currently reading. It also allows users to rate each
book they have read. The recommendation feature
should suggest books based on the user's list of
books they have read and rated. The recommendations
will come from a large language model (LLM) that
supports structured output.
"""
epic = client.responses.parse(
model="gpt-4o",
input = [
{ "role": "system", "content": SYSTEM_PROMPT },
{ "role": "user", "content": USER_PROMPT }
],
text_format=Epic,
).output_parsed # type: Epic | None
if epic is None:
print("OpenAI did not return a valid response.")
else:
epic_json = epic.model_dump_json(indent=4)
print(epic_json)
We get back the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
{
"title": "Book Recommendation Feature",
"description": "Integrate a recommendation feature in the book management application to suggest books based on users' reading history and ratings.",
"features": [
{
"title": "Recommendation Algorithm",
"description": "Develop the core algorithm to recommend books using a large language model.",
"user_stories": [
{
"title": "Integrate LLM for Recommendations",
"description": "As a user, I want the app to suggest books based on a large language model using my reading history and ratings.",
"acceptance_criteria": "Books recommended align closely with the user's reading preferences and ratings.",
"story_points": "8",
"tasks": [
{
"title": "Analyze User Data Attributes",
"description": "Identify which data points (e.g., genres, ratings) should be sent to the LLM."
},
{
"title": "LLM API Integration",
"description": "Connect to the LLM API and ensure the data is correctly formatted for input."
},
{
"title": "Recommendation Output Handling",
"description": "Design system to interpret and display structured output from the LLM."
}
]
}
],
"spikes": [
{
"title": "Evaluate LLM Providers",
"description": "Research and determine the best LLM provider for book recommendations.",
"tasks": [
{
"title": "Assess LLM Accuracy",
"description": "Run tests with different LLMs to evaluate accuracy in book recommendations."
},
{
"title": "Cost Analysis",
"description": "Analyze the cost implications of each LLM provider given expected usage."
}
]
}
]
},
{
"title": "User Interface Enhancements",
"description": "Improve the application interface to support the recommendation feature.",
"user_stories": [
{
"title": "Recommendation Display",
"description": "As a user, I want to see a list of recommended books on my dashboard so I can explore new titles.",
"acceptance_criteria": "Recommended books are visible on the user's dashboard with relevant details.",
"story_points": "5",
"tasks": [
{
"title": "Design Mockups",
"description": "Create design mockups for the recommendation section on the dashboard."
},
{
"title": "Implement UI Elements",
"description": "Develop front-end components to display recommended books and their details."
},
{
"title": "User Feedback Mechanism",
"description": "Add functionality for users to rate recommendations for feedback."
}
]
}
],
"spikes": [
{
"title": "Evaluate UI Frameworks",
"description": "Analyze frameworks and libraries that could enhance UI design for the recommendations.",
"tasks": [
{
"title": "Compare UI Options",
"description": "Review and compare different UI libraries for efficiency and style."
},
{
"title": "Prototype with Selected Library",
"description": "Create a basic prototype using the chosen UI framework."
}
]
}
]
}
]
}
Not bad for such a basic description! Now let’s work on getting this output directly into Azure DevOps. We need a Personal Access Token (PAK), generated from within Azure DevOps, to use the Python SDK. I’ve placed mine in my .env as AZURE_DEVOPS_PAK. I asked ChatGPT o4-mini-high to give me some examples of creating work items using the Azure DevOps Python SDK, including assigning parent relationships to new items. I took its examples and turned them into the two functions below, which will simplify the process of building out our epic.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import os
from msrest.authentication import BasicAuthentication
from azure.devops.connection import Connection # type: ignore
from azure.devops.v7_1.work_item_tracking import WorkItemTrackingClient # type: ignore
from azure.devops.v7_1.work_item_tracking.models import JsonPatchOperation # type: ignore
def create_item(
work_item_client: WorkItemTrackingClient,
title: str,
work_item_type: str,
project: str,
additional_values: dict | None = None,
parent_url: str | None = None,
):
"""Create a work item in Azure DevOps."""
patch = [JsonPatchOperation(op="add", path="/fields/System.Title", value=title)]
if additional_values:
for key, value in additional_values.items():
patch.append(
JsonPatchOperation(op="add", path=f"/fields/{key}", value=value)
)
if parent_url:
# Link this new item under the given parent
patch.append(
JsonPatchOperation(
op="add",
path="/relations/-",
value={
"rel": "System.LinkTypes.Hierarchy-Reverse",
"url": parent_url,
"attributes": {"comment": "Linking under parent"},
},
)
)
wi = work_item_client.create_work_item(patch, project=project, type=work_item_type)
print(f"Created {work_item_type}: ID={wi.id} {title}")
return wi
def create_child_tasks(work_item_client: WorkItemTrackingClient, tasks: list[Task], project: str, parent_url: str):
"""Create child tasks under a parent work item."""
for task in tasks:
create_item(
work_item_client=work_item_client,
title=task.title,
work_item_type="Task",
project=project,
additional_values={
"System.Description": task.description,
},
parent_url=parent_url,
)
Finally, we can use our new functions to build out our epic in DevOps:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
access_token = os.getenv("AZURE_DEVOPS_PAK")
if not access_token:
raise ValueError("AZURE_DEVOPS_PAK environment variable not set.")
organization_url = "https://dev.azure.com/<your org name>"
devops_project = "Sandbox"
credentials = BasicAuthentication("", access_token)
connection = Connection(base_url=organization_url, creds=credentials)
wit_client = connection.clients.get_work_item_tracking_client()
if epic:
devops_epic = create_item(
work_item_client=wit_client,
title=epic.title,
work_item_type="Epic",
project=devops_project,
additional_values={
"System.Description": epic.description,
},
parent_url=None,
)
for feature in epic.features:
devops_feature = create_item(
work_item_client=wit_client,
title=feature.title,
work_item_type="Feature",
project=devops_project,
additional_values={
"System.Description": feature.description,
},
parent_url=devops_epic.url,
)
for user_story in feature.user_stories:
devops_user_story = create_item(
work_item_client=wit_client,
title=user_story.title,
work_item_type="User Story",
project=devops_project,
additional_values={
"System.Description": user_story.description,
"Microsoft.VSTS.Common.AcceptanceCriteria": user_story.acceptance_criteria,
"Microsoft.VSTS.Scheduling.StoryPoints": user_story.story_points,
},
parent_url=devops_feature.url,
)
create_child_tasks(work_item_client=wit_client, tasks=user_story.tasks, project=devops_project, parent_url=devops_user_story.url)
for spike in feature.spikes:
devops_spike = create_item(
work_item_client=wit_client,
title=spike.title,
work_item_type="Spike",
project=devops_project,
additional_values={
"System.Description": spike.description,
},
parent_url=devops_feature.url,
)
create_child_tasks(work_item_client=wit_client, tasks=spike.tasks, project=devops_project, parent_url=devops_spike.url)
print("All items created successfully.")
After executing the above, we can take a look in DevOps at our new epic:
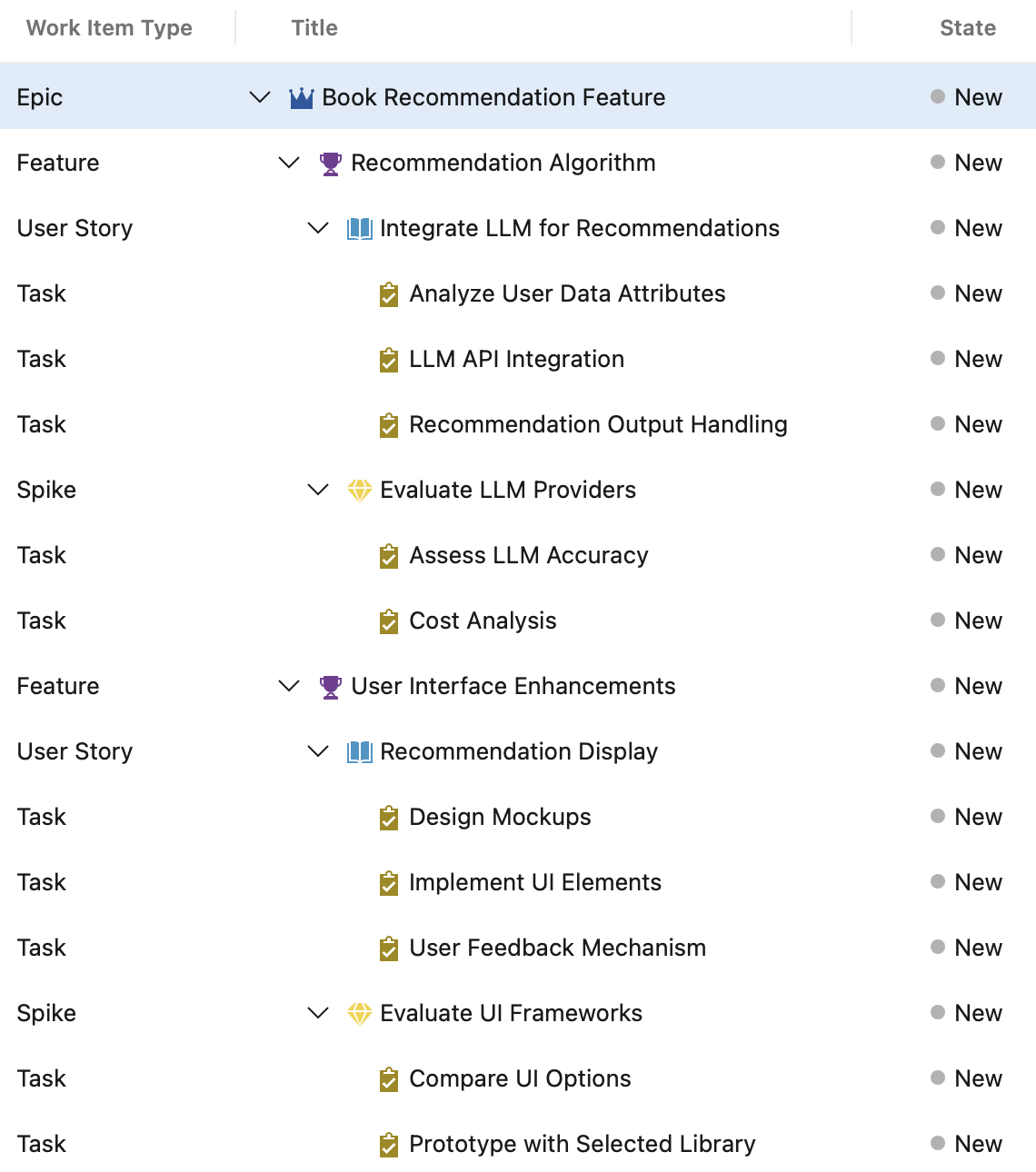
Given the minimal context I provided, it did a decent job. I can already imagine a number of ways we could extend this into a useful product:
- Provide previous project descriptions and resulting epics in the prompt so that the LLM tailors its generated epics to our internal style.
- Present the new epic and associated work items in a simple UI that allows a project manager to tweak the results before sending it to Azure DevOps.
- Multimodal LLMs support text and image input - perhaps some projects might benefit from having images included along with the project description.
Final thoughts
The structured output feature of LLMs makes it possible to take unstructured input, such as text and images, and convert it into output that can be programmatically consumed by other systems, especially databases and APIs. There is almost certainly a lot of low-hanging fruit out there to harvest with small LLM integrations that reduce the human effort needed to interact with complex software. The Azure DevOps example was only about 200 lines of Python code!